Every local LLM tutorial throws around cryptic labels like Q4_K_M, Q5_0, Q8_0. Nobody explains what they mean. Here’s the plain-English version: quantization shrinks model weights from 16-bit floats down to 4 or 2 bits each, trading a little quality for a LOT of VRAM savings.
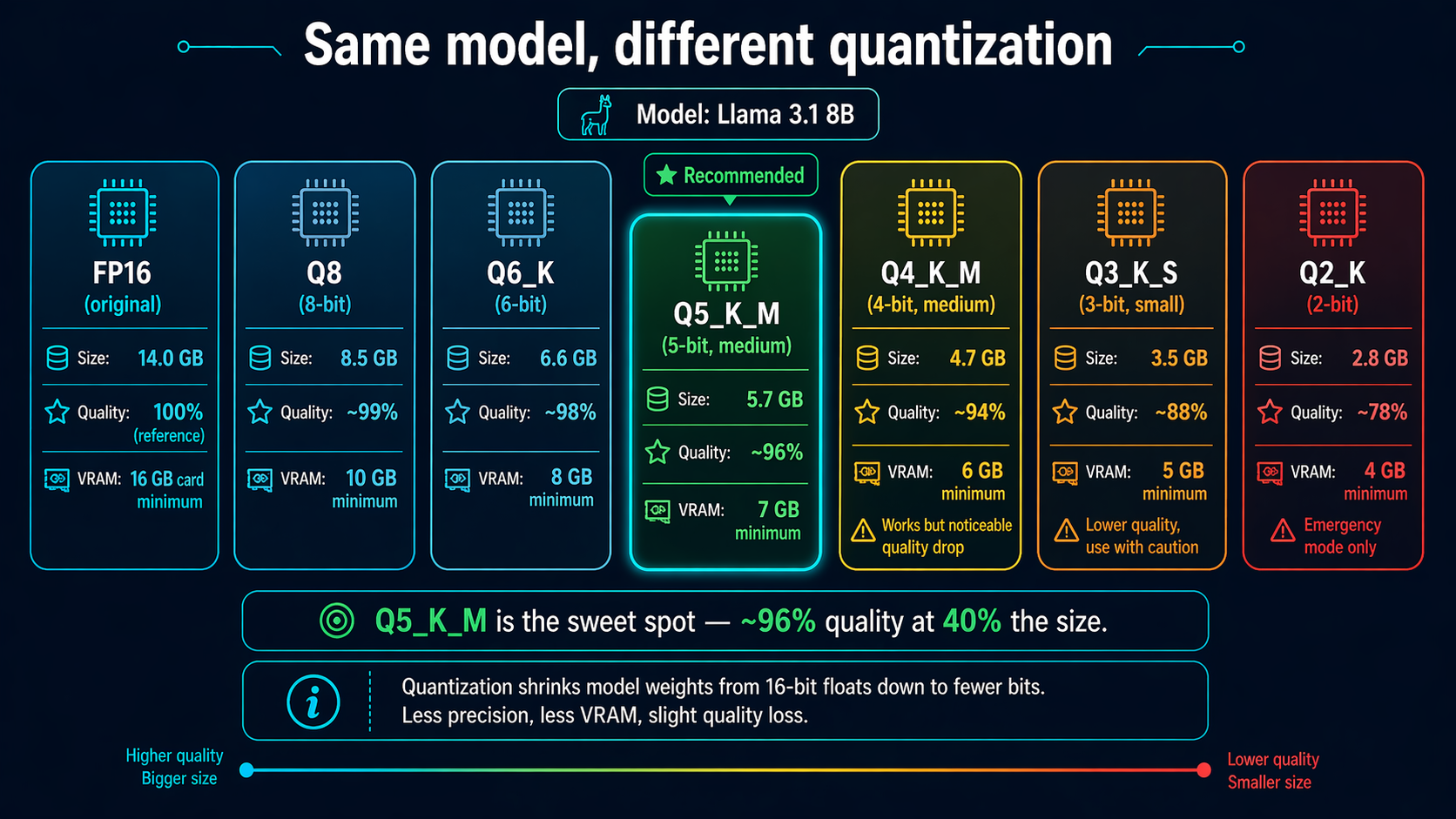
The quantization ladder
FP16 — the original, full precision
Size: 14 GB (Llama 3.1 8B) · Quality: 100% · VRAM: 16 GB minimum
What the model was trained as. Only worth running if you have the VRAM and need benchmark-grade quality.
Q8_0 — 8-bit, near-reference
Size: 8.5 GB · Quality: ~99% · VRAM: 10 GB
Effectively lossless. If you have the VRAM, this is the highest reasonable quant for production work.
Q6_K — 6-bit, strong balance
Size: 6.6 GB · Quality: ~98% · VRAM: 8 GB
Barely distinguishable from Q8 in blind testing. Good for 8GB cards that want max quality.
★ Q5_K_M — the sweet spot
Size: 5.7 GB · Quality: ~96% · VRAM: 7 GB
The consensus “best bang for buck” quant. Barely noticeable quality loss, ~40% the size of FP16. If you don’t know which quant to pick, pick this one.
Q4_K_M — 4-bit, most popular
Size: 4.7 GB · Quality: ~94% · VRAM: 6 GB
The de-facto default on HuggingFace. Noticeable but acceptable quality drop. Best when you need to fit a model on tight VRAM.
Q3_K_S — 3-bit, compact
Size: 3.5 GB · Quality: ~88% · VRAM: 5 GB
You’ll notice clunkier responses and occasional coherence issues. Only use if Q4 won’t fit.
Q2_K — 2-bit, emergency mode
Size: 2.8 GB · Quality: ~78% · VRAM: 4 GB
Use ONLY when you absolutely need to fit a big model on small VRAM (e.g., Llama 70B on a 24GB card). Noticeable quality degradation.
What do those cryptic letters mean?
- Q = quantized (vs. F for full precision)
- The number (Q4, Q5, Q8) = how many bits per weight
- _K = uses K-quants (newer, better quality than old _0 / _1)
- _M = “medium” — intermediate importance weights kept at higher precision
- _S = “small” — more aggressive compression, less quality
- _L = “large” — less aggressive compression, more quality
So Q5_K_M = 5-bit quantization using K-quants with medium-tier quality preservation. In 99% of cases you want _K_M variants.
Which quant should I pick?
| Your situation | Recommended quant |
|---|---|
| “I have a 24GB card and want maximum quality” | Q8_0 or Q6_K |
| “I want best balance of quality and size” | Q5_K_M ★ |
| “I want to run a bigger model than my VRAM normally allows” | Q4_K_M |
| “I’m fitting a 70B on a 24GB GPU” | Q2_K (painful but works) |
| “I’m fitting a 405B on 80GB” | Q4_K_M or Q3_K_M |
Related guides
- 🛠 Interactive hardware checker
- 💾 VRAM requirements by model size
- ⚡ Tokens-per-second benchmarks
- 💰 Best GPU for local LLMs by budget
Last updated: 2026-04-22.