
I spent three years building dashboards in raw Prometheus queries. Nothing fancy. Just PromQL in rectangles, refreshing every 30 seconds, occasionally alerting when the disk got stupid. It worked. I knew where everything was. But it was also exactly as fun as it sounds.
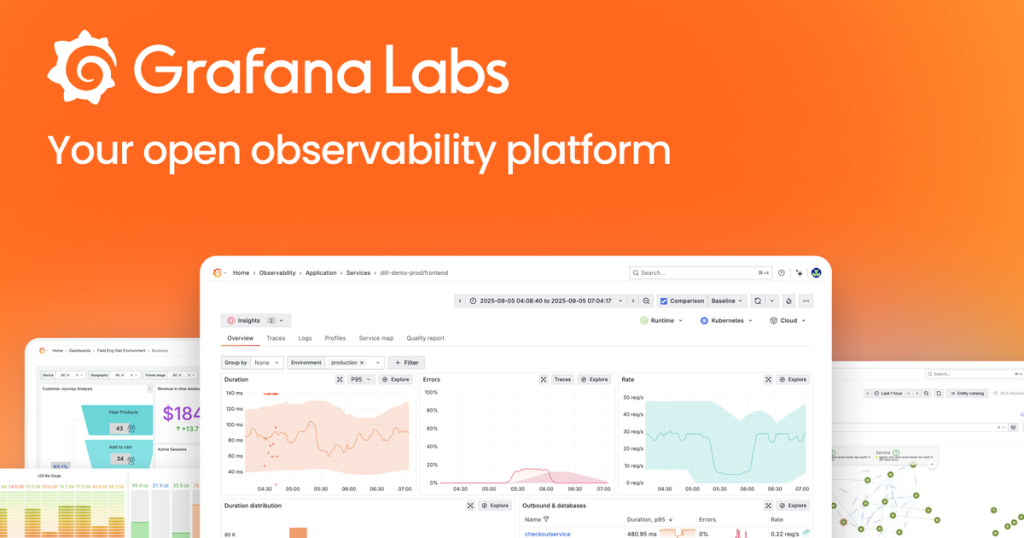
Last spring I started hearing about Grafana’s natural language query feature and the ML anomaly detection. Sounded interesting. Also sounded like the kind of thing that would break on a Tuesday and eat two hours of my evening. But the alternative was writing another hand-crafted dashboard for application latency, and I was tired enough that I just set up a test instance.
The move: what actually made sense
First thing: I already had Prometheus scraping everything. Grafana’s Prometheus plugin is just there. You point it at your scrape targets, set the retention to 15 days instead of forever, and suddenly you have a cleaner interface on top of what you were doing anyway. That part took maybe 20 minutes.
The natural language query feature is the thing that actually changed my workflow. Instead of writing rate(http_request_duration_seconds_sum[5m]) / rate(http_request_duration_seconds_count[5m]) to see average request latency, I can ask it in English. “Show me average request latency over the last 24 hours by endpoint.” It parses that and generates the PromQL underneath.
I was skeptical. I still am, a little. But it works more often than it doesn’t. You get a SQL-like query builder as fallback, which is actually useful when the AI interpretation misses the mark. And unlike a lot of AI features that exist mainly as marketing checkboxes, this one saved me real time because I wasn’t memorizing PromQL edge cases.
The anomaly detection is where things got interesting. You can point it at a metric and tell it to learn what “normal” looks like over a week or two, then alert on deviations. I set it on disk I/O for my NAS. Two days in it flagged something weird: sustained high write activity at 4 AM. I didn’t know about that. Turned out a backup job was thrashing the array because I’d misconfigured the thread pool. Would’ve caught it eventually, but not for another month probably.
The gear I run for this
Hardware from my own homelab, relevant to this guide — direct Amazon links.
Affiliate links — I earn a small commission at no extra cost to you. Browse my full homelab store →
The friction
The AI features aren’t free. Not in money—Grafana’s still open source and self-hostable. But they require connections to Grafana Cloud for the actual inference. You can’t run it all locally. That bothered me more than it should have. I run a homelab specifically to keep things local. But the tradeoff is clear: either I maintain ML infrastructure myself or I accept some cloud calls for intelligence.
I chose cloud calls. Mostly. Still doesn’t feel great, but it’s not egregious. Grafana isn’t sending your raw metrics anywhere. It sends anonymized excerpts and metadata. I read their docs on this. Still a compromise, but a manageable one.
The other gotcha: you need actual cardinality in your metrics for the AI stuff to be useful. If you’re scraping 40 identical instances with no labels, Grafana’s natural language queries will work but they’ll also be boring and uninformative. I had to go back and clean up years of lazy metric naming. That was tedious. Worth it, but tedious.
What I actually miss
I don’t miss raw Prometheus dashboards the way you might miss an old car. But there’s something to be said for complete, visible control. With PromQL, every query is explicit. You know exactly what you’re asking for. With the AI layer, sometimes Grafana interprets your English question in ways you didn’t expect. You get a query you didn’t write. Usually it’s fine. Sometimes you have to click through, read the generated PromQL, and adjust manually.
That’s not a complaint, really. It’s just the tax you pay for convenience.
I also miss the simplicity of having one less moving part. Grafana is another service running on another port (3000 in my setup), another database backing it, another potential failure point. My old Prometheus setup was leaner. Fewer things to break at 2 AM.
Six months in
I’m still using it. I’ve built maybe eight dashboards since the migration. The natural language feature gets used for quick ad-hoc queries more than for permanent dashboard panels. The anomaly detection is running on maybe 15 key metrics now. It’s caught things I would have caught manually, just faster.
Would I do it again? Yeah. But I’m not evangelizing it. Some labs don’t need the extra layer. If you’re happy with PromQL and you’re not missing root cause detection, raw Prometheus is still plenty. But if you’re at the point where writing dashboards feels like busy work and you’re willing to trade some local control for better defaults, Grafana’s AI features do actually deliver something.
The next question I’m wrestling with is whether to trust the Sift automated root cause analysis, or whether I should keep running my own incident response checklist. That’s the article I’ll probably write next.
Explore Grafana + AI in our AI Homelab Toolkit.